Daily Pulse · · macro · ARM

The AI trade isn't running out of air. It's relocating.
What looks like fatigue at the top of the semiconductor complex is not the hype deflating — it's a graduated shift down the stack, from the capex layer to the layer that gets paid when those chips are actually used. The job here was never to time entries and exits in “the AI trade.” It's to position along the waves. Right now that means one thing: trimming tactical semiconductor exposure in the Rubin Build-Out and adding the names that earn when agents get deployed at scale.
Three stages, repeating in waves
The cycle runs in three stages, and they are not a one-time event:
- Stage 1 — the AI capex cycle. Compute gets built. Multiple sub-cycles — equipment, memory, packaging, substrates, power, cooling, optical — rotate through leadership. GPU-dominated, NVIDIA-centric.
- Stage 2 — the AI opex cycle. Agentic infrastructure. The names that get paid per unit of machine activity once the compute is running.
- Stage 3 — AI applications. End-user value capture.
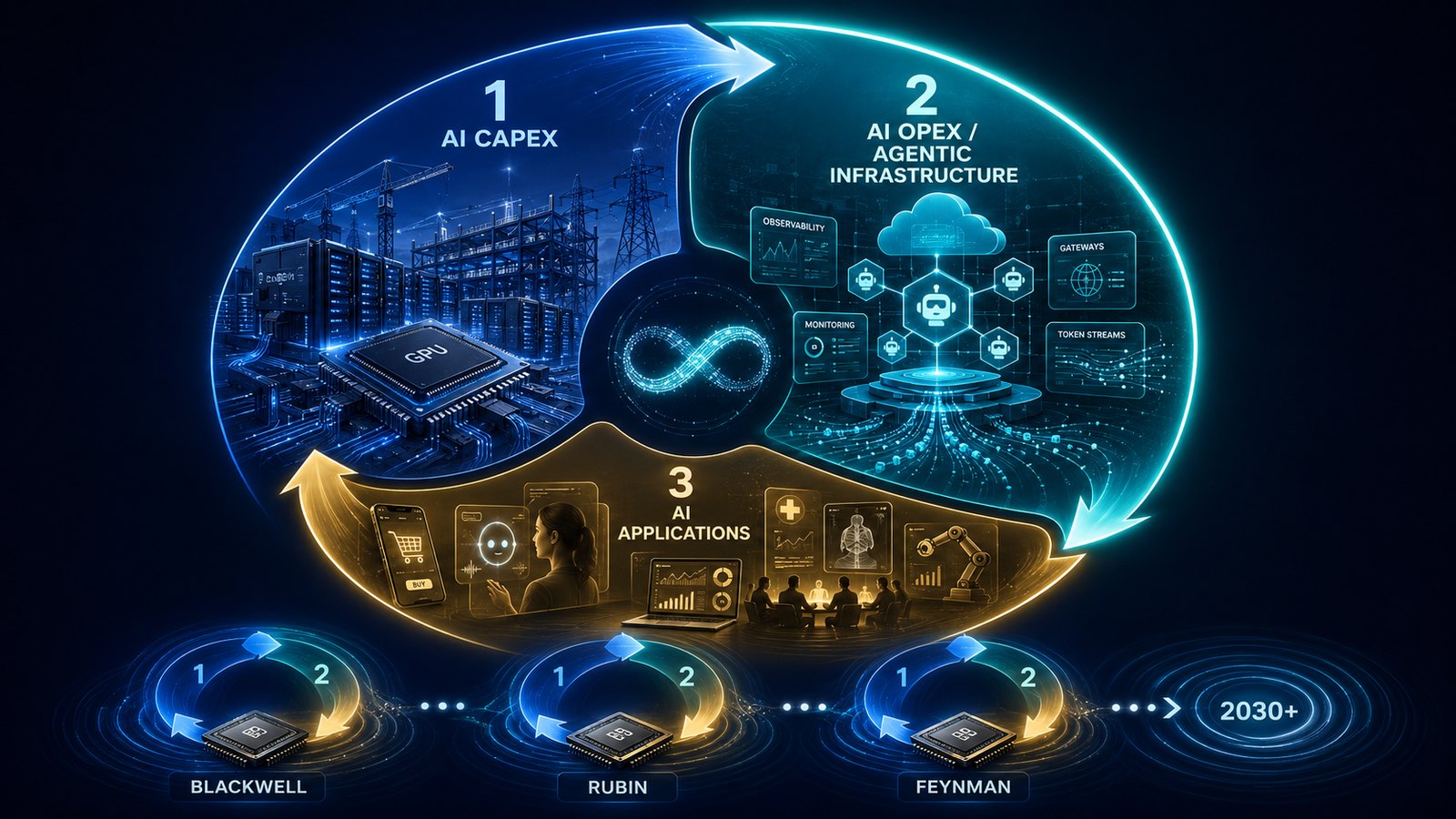
The trigger that moves the market from Stage 1 to Stage 2 is a step-change down in token cost — the point at which agents are not just deployable, but deployable at a margin. And the whole sequence repeats: each new NVIDIA generation — Blackwell → Rubin → Feynman — kicks off a fresh Stage 1, which in turn seeds the next Stage 2. That cadence runs to at least 2030. We are at the Stage 1 → Stage 2 handover now.
The trigger is pulling forward
Three forces are converging on the token-cost collapse at the same time:
- The Rubin rollout. The Vera Rubin platform is in full production, with cloud availability through H2 2026. NVIDIA's own figure is up to a 10× reduction in inference cost per token versus Blackwell — the Stage-1 engine now directly feeding Stage 2. (The economics of that step-down are the subject of our inference economics primer.)
- The April 2026 Chinese frontier wave. Five labs shipped frontier-tier models inside a four-week window — GLM-5.1 (754B, MIT-licensed, trained entirely on Huawei Ascend silicon), Kimi K2.6, DeepSeek V4 (production tier near $0.14 per million tokens), and Qwen 3.6. The point for positioning is not the leaderboard — it's the 5–30× lower cost of access, and that gap is structural, not promotional.
- TurboQuant. Google's KV-cache compression (ICLR 2026) cuts inference memory roughly 6× and speeds attention up to 8× on H100-class hardware — software-only, training-free, with no measurable accuracy loss. The same GPU now serves far more concurrent agents at long context.
Stack them, and the unit economics of running an agent flip from demo to deploy-at-margin. That is the trigger — not a louder narrative, a cheaper one.
The CPU tell: the host, not just the GPU
The sharpest validation of the handover didn't come from a software chart. It came from NVIDIA. With Vera — the ARM-based host CPU of the Rubin platform, 88 custom Olympus cores — NVIDIA built and branded “the CPU for agents,” and made our exact argument out loud: the next bottleneck in AI infrastructure is no longer the GPU, but the host processor that runs the agent-orchestration loop around it.
The mechanics are the thesis. A single chat completion barely touches a CPU. An agent is different — it plans, dispatches tools, spins up code sandboxes, hits retrieval stores, and aggregates results, often dozens of times per request, across thousands of concurrent sessions. That control flow, the KV-cache management, the sandbox concurrency — that is CPU work. As Rubin, the Chinese frontier wave, and TurboQuant collapse the per-token GPU cost, the binding constraint migrates to how many agent loops a host can keep alive at once. The GPU getting cheaper is precisely what elevates the CPU above it.
The rotation, in three axes
This is the operational meaning of last week's point: the opex group is not Enterprise SaaS. The tell is the billing model, not the sector label. Consumption-based infrastructure that meters machine activity is showing relative strength against seat-based software — because agents are the thing that generates the requests, the telemetry, the messages, the compute-hours. We capture the move across three axes.
Axis 1 — Consumption infrastructure
The metered layer that scales with agent activity rather than human headcount: Cloudflare (NET) — edge requests and Workers; Datadog (DDOG) — observability, usage-billed; Twilio (TWLO) — communications APIs, per event; DigitalOcean (DOCN) — low-cost compute for running agents.
Axis 2 — Edge
Where the agent actually executes, on two sides of the same boundary: the software edge — Cloudflare (NET), agent code metered per request; and the silicon edge — Qualcomm (QCOM), on-device agents across AI PCs, mobile and automotive.
Axis 3 — Agentic CPU
The host and orchestration layer NVIDIA's Vera just legitimized:
- ARM (ARM) — the anchor. The ISA under Vera, under every hyperscaler custom CPU (Graviton / Axion / Cobalt), under the edge device, and under NVIDIA's coming AI-PC silicon. Its royalty model is a consumption model — it earns per unit shipped, the same shape as NET and DDOG earning per request. The one semiconductor name that behaves like an opex name.
- AMD (AMD) — the merchant host. EPYC as the leading purchasable host CPU for AI servers, plus a credible second accelerator line — the way to own the agentic-host build-out without it being captive inside a single GPU vendor.
- Qualcomm (QCOM) — the edge expression. Carried over from Axis 2; ARM underneath.
One structural note that sharpens the trade: Vera itself is captive — you only get it by owning the GPU vendor, which is primarily a Stage-1 name. The un-captive expressions of the agentic-CPU thesis are therefore ARM, AMD and Qualcomm — the sleeve lets you play Stage 2 without adding Stage-1 GPU beta. The mirror image is seat-based Enterprise SaaS: agents compress headcount, so software priced per human carries a structural question even while the AI tape runs hot. The relative-strength divergence is the market beginning to separate the AI tax collector on machine activity from software priced per person.
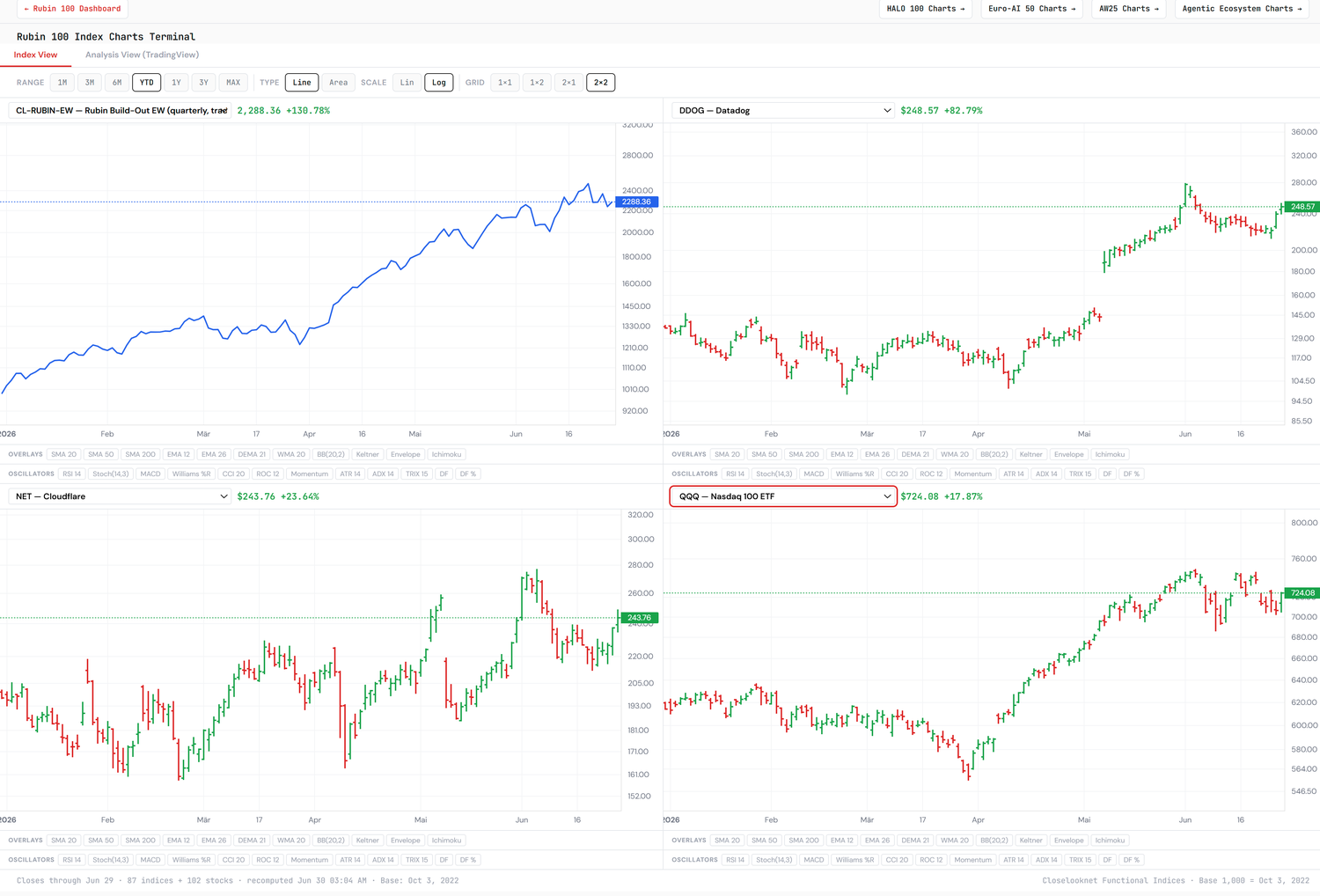
What it means for the three indices
The handover reads directly as a rebalancing across our books:
- Rubin Build-Out — trim tactical, late-cycle semiconductor exposure into strength. The build-out thesis is intact for the next generation; the tactical leadership is rotating.
- Agentic Ecosystem / Agentic Winners — add along all three axes above. The agentic-CPU sleeve (ARM / AMD / QCOM) is the newly-formalized leg.
Live index levels update on their own pages: Rubin Build-Out · Agentic Ecosystem · Agentic Winners 40.
Editor's note: the Closelook indices run their scheduled rebalance tonight, after the close — the first semi-annual reconstitution — so the refreshed three-tier ecosystem (build → operate → use) will be reflected on the index pages from tomorrow onward.
This is reference-portfolio positioning logic, not a call to the reader — publishing and money management remain separate. The point is the direction of the rebalance, and it is one-way at the handover: from the layer that builds the compute to the layer that gets paid for using it.
The cross-current worth holding in view
The same token-cost collapse that powers the opex trade is ambivalent for memory. When TurboQuant printed, memory names — Micron, SK Hynix — sold off, on the read that aggressive KV-cache compression reduces memory demand per query. The resolution is Jevons. Cheaper inference drives vastly more inference; net memory demand rises even as per-query memory falls. That reinforces the Stage-1 → Stage-2 logic rather than breaking it. But near-term, if compression sentiment outruns the demand-growth print, the memory co-clock takes an air-pocket. Hold both in view; don't let the compression headline be read as a structural short on memory.
What would break this
The honest counter-edge: the consumption sleeve has higher beta to the thesis than the semis it replaces. It is a bet not only that Stage 2 arrives, but that it arrives on time. If agent adoption stalls — cost still too high in practice, reliability not yet there — usage-based names de-rate faster on the way down than seat-based software does, precisely because their revenue is tied to activity that hasn't materialized yet. Sizing should respect that asymmetry. The trade is right if, and while, the token-cost line keeps falling and the relative-strength divergence keeps widening. Both are observable. Watch them, not the narrative.
Sources for the data points above (paraphrased, for reference): NVIDIA Vera Rubin platform and Vera CPU announcements; coverage of the April 2026 Chinese frontier-model wave; TurboQuant (Google Research / DeepMind, ICLR 2026).