Heresy · 11:00 CET
The Model Is Not the Moat — Closelook Heresy XI
Own Your Own Weights, Own Your Own Harness — and why the frontier labs may become suppliers, not platforms.

Two of the largest compute owners on Earth just became landlords. The tell isn't that scarcity is ending — it's that owning the biggest model and the biggest cluster was never the moat. The moat is the harness bred around the model.
The dominant AI story is still told as a model story. Who has the biggest model. Who tops the benchmark. Who reaches the next frontier first. That story is not wrong. It is simply no longer sufficient — and the two most revealing events of the last eight weeks were not model releases at all. They were leases.
This is the heresy.
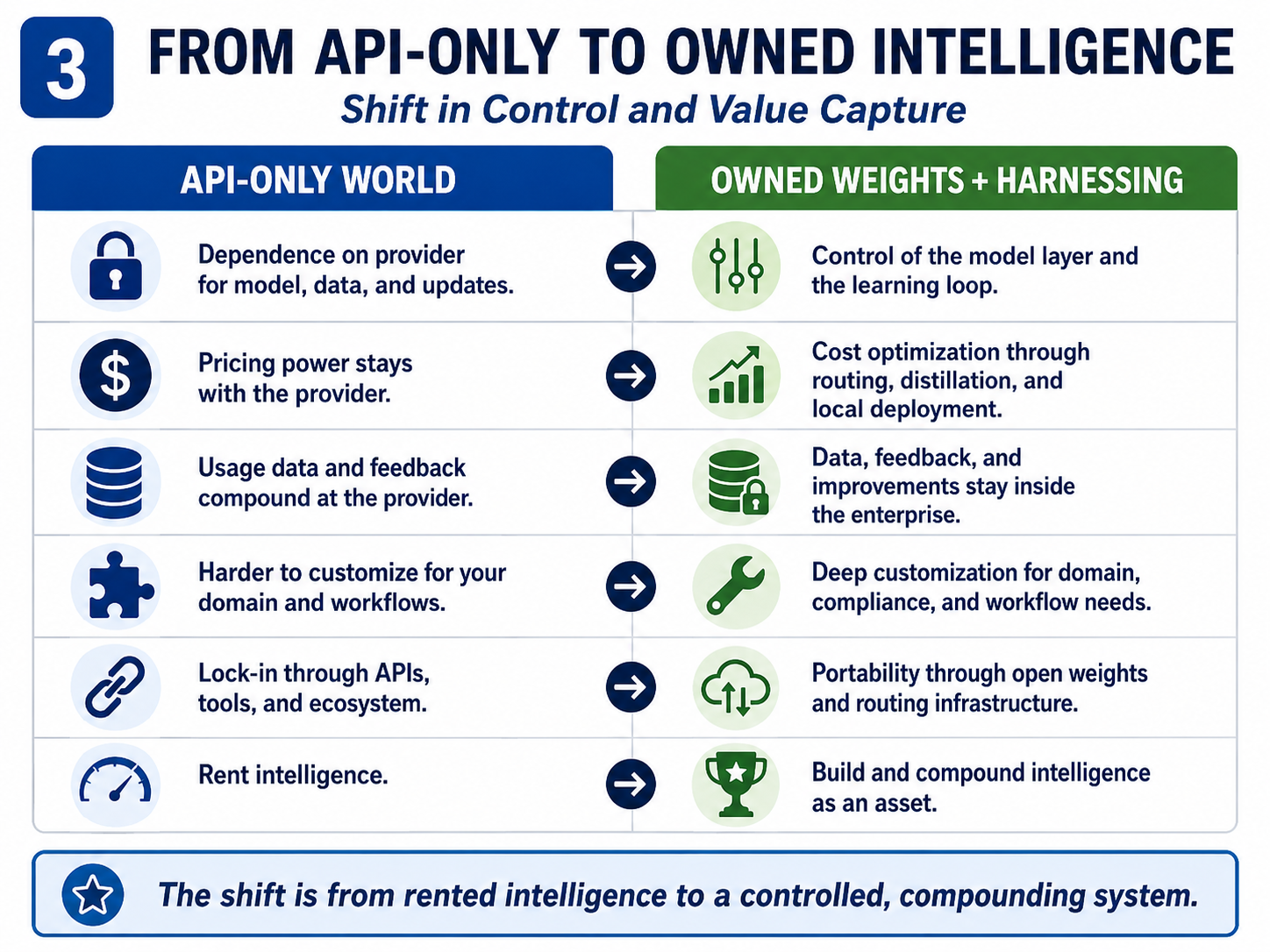
The heresy: The winning enterprise AI architecture may not be a company renting intelligence from one proprietary frontier model. It may be a company that controls a portfolio of open-weight models, orchestrates them by task, wraps them in proprietary harnesses, and uses meta-harnessing to continuously breed better workflows, agents and applications. In that world the frontier model still matters — but it stops being the operating system and becomes one component inside a larger intelligence stack.
The entry phrase for this shift is own your own weights. The deeper phrase is own your own harness. And the phrase that decides the next decade may be own the process that improves the harness. That is where the compounding lives — and it is not, primarily, where the frontier labs sit.

1. Three regimes of intelligence
A model is its weights — the learned parameters that determine how it responds to language, code, context and tool calls. If you do not control the weights, you do not control the model. You have access to it. There are three regimes, and the distance between them is the whole argument.
Rented intelligence (API-only). You send prompts to a provider; the provider runs a closed model; you receive outputs. Powerful, simple, immediate. But you inherit the provider's pricing, roadmap, safety policy, latency, data terms and model-behaviour changes. This is the dominant frontier regime, and it is where most of today's AI valuations are anchored.
Controlled intelligence (open-weight). The weights are released under a licence. You can host, fine-tune, quantize, distil, route and embed the model inside your own infrastructure. Not always “open source” in the strict sense — licences differ — but the object itself moves under your control.
Owned intelligence (proprietary internal). You fine-tune an open-weight base on your own data, deploy it privately, and run a family of internal variants specialised to your workflows. This does not mean every company trains a frontier model from scratch — that would be absurd. It means owning the adapted, deployed, controlled version of the intelligence layer that actually runs your business.
The move that matters is the move from access to control. Everything downstream follows from it.

2. What this threatens
The closed-frontier business model wants to become the central API layer of intelligence — the operating system of enterprise AI. In that dream, enterprises never own the core layer; they rent it, and every incremental workflow pours more volume through the meter while the provider keeps the weights, the upgrade path, the pricing schedule, the developer ecosystem and — critically — the learning loop.
“Own your own weights” attacks that dream at the level of value capture, not capability. It says: do not outsource the institutional learning system of the company. Do not let your most valuable workflow traces, corrections, routing logic and domain adaptations compound primarily inside somebody else's stack.
If frontier APIs become the premium fallback rather than the default engine, the pricing power changes and the monopoly-utility thesis weakens. The question stops being “who has the best model?” and becomes: how much of enterprise AI value is created by the raw model, and how much by the system wrapped around it? The answer is migrating toward the system.
3. The landlord tell — why the compute-renters are the ones who lost the model race
Here the sceptic interrupts. Wait: two of the largest compute owners on the planet just started renting capacity out. Doesn't that mean the model race is cooling, demand is soft, and this whole thesis is moot?
The opposite. Read correctly, the leases are the cleanest confirmation of the heresy we have.
SpaceX / xAI. After merging with xAI in early 2026, SpaceX leased essentially all of its Colossus 1 supercomputer in Memphis — over 220,000 NVIDIA GPUs and 300+ megawatts — to Anthropic, at roughly $1.25 billion per month through 2029 (about $15bn a year, some $45bn over the life of the deal). Weeks later it signed Google to roughly $920 million per month for about 110,000 GPUs — capacity Google itself described as short-term “bridge” supply for surging Gemini Enterprise demand — with a third arrangement reported alongside an open-source lab. Both contracts carry 90-day exit clauses after end-2026.
Now the tell. Colossus 1 was reportedly running at about 11% Model FLOPs Utilization — “embarrassingly low” in an internal memo — because its mixed H100/H200/GB200 fabric couldn't parallelise Grok training cleanly. xAI decamped its training to Colossus 2. Its team had walked out months earlier; Musk conceded Grok needed a rebuild; the AI segment posted an operating loss of roughly $2.5bn on ~$818m of revenue in Q1. The most capable single cluster in the country was sitting idle because the model it was built for failed to generate demand. Renting it out — at a premium, on short leases, ahead of an IPO — was the rational way to turn a stranded asset into cash flow until the next model is ready.
Meta. On 1 July, Meta was reported to be standing up “Meta Compute,” a cloud business to sell excess AI capacity and hosted models to outsiders. Two service shapes: raw GPU capacity (the CoreWeave pattern) and paid developer access to hosted models — including its closed-weight Muse Spark — in an AWS-Bedrock arrangement. The stock jumped ~9–10% on the day; CoreWeave fell ~14% and Nebius ~17%.
Sit with the second half of that. Meta was supposed to be the Western open-weight champion. Llama was the answer to “who owns the genetic pool.” And Llama has fallen behind — materially, and most painfully against Chinese open-weight models — while morale and the model roadmap wobbled. The pivot to selling excess compute and fronting a closed model is the open-weight champion quietly conceding its own race. This is not a company monetising abundance from a position of strength. It is a company de-risking its earnings because the model bet underdelivered.
So the correct reading of the two great leases of 2026 is not scarcity is ending. It is:
- The sellers are the losers of the model layer. xAI and Meta owned frontier-scale compute and placed direct bets on model supremacy — and both stumbled at the model, not the metal. When your model fails to generate inference demand, your world-class cluster becomes a landlord's asset you rent to your rivals. That is the opposite of a moat. Owning the biggest compute and betting on the biggest model did not secure defensibility. That is the heresy, stated by the market itself.
- The buyers prove scarcity persists. Anthropic paid a strategic premium for all of Colossus 1 the same day it raised Claude usage limits; Google bought “bridge capacity” because Gemini Enterprise demand ran ahead of expectation. Nobody who can sell capacity struggles to find a buyer instantly. Frontier tokens remain scarce and command a premium.
- The token/revenue split is bifurcating, not collapsing. The plausible steady state is roughly 80% of tokens flowing to cheap, “good-enough” open models and ~20% to frontier SOTA — but that expensive 20%, aimed at mission-critical work, keeps a disproportionate share of the revenue. Enterprise spending data (e.g. the Ramp AI Index) already shows extreme concentration: a small cohort of power-user firms spends orders of magnitude more per employee than the median. Tokens spread out to the cheap tier; dollars cluster at the top.
The 20/80 question — and a more radical branch. It is worth slowing down here, because this third point hides the single largest disagreement in AI economics, and it turns on a distinction most commentary blurs. There are three different splits, not one: token share (how much of the volume runs on which models), revenue share (how the dollars divide) and value share (where the durable margin sits). They are not the same number, and the entire frontier-lab valuation case lives in the gap between them.
The constructive base case — the one the bulls advance — grants that cheap, good-enough models take ~80% of the tokens but insists the frontier keeps most of the revenue, because the hardest, highest-stakes work always reaches for the best model and pays up for it. On this reading the split is stable: volume commoditises, dollars concentrate, and the frontier sits on the premium 20% that carries the liability, the willingness-to-pay and the reputational cover. The concentration in enterprise spend is offered as early confirmation.
But there is a more radical branch worth stating plainly — as a line of thinking, not a forecast: over a long horizon the frontier may capture only ~20% of the business too, its revenue share converging down toward its token share. The mechanism is that “as good as necessary” is not a fixed line but a rising floor. Each year, harnessing plus open-weight progress lets cheaper models clear that floor on a widening set of tasks that used to demand the frontier. Work migrates, quietly and permanently, out of the “needs the best model” column into the “good-enough model plus strong harness” column — and it does not migrate back. In that world the premium tier keeps shrinking toward the genuine research edge: the true exceptions, the un-harnessable hard cases, and the newest capability in the window before it too commoditises.
Which world obtains is not a matter of taste; it turns on one race. Does the frontier keep opening a capability gap fast enough to create new premium tasks as quickly as harnessing commoditises the old ones? If yes, the base case holds and revenue share sticks near the top. If harnessing and open weights close the gap on the highest-value tasks faster than the labs can open new ones, the radical branch wins and frontier revenue erodes toward frontier token share. One durable counterweight the bears underweight: willingness-to-pay is not only about capability. Buyers pay a premium for assurance — the liability cover and reputational safety of running the best model on a mission-critical call — and that premium can persist long after the raw quality gap has closed. Risk-aversion economics may hold the frontier's revenue share up even as its capability lead commoditises.
The honest read is that neither pole is the destination; the path is a glide. Frontier revenue share plausibly starts where the bulls say — high, well above token share — and drifts toward, though probably not all the way to, its token share as harnessing matures, with the speed of the drift set by how fast the labs keep manufacturing genuinely new premium capability. And here is the point that matters for this Heresy: it does not require the radical branch to be right. It requires only the direction — the frontier sliding from “most of the revenue” toward “the hard exceptions.” Because wherever the split lands, the incremental value — the margin on every task that moves from premium to good-enough — accrues to whoever built the harness that moved it. The tell to watch is narrow and real: whether the frontier's revenue-per-token premium is holding or compressing inside mature enterprise deployments. That number, not any benchmark, tells you which world you are living in.
None of this kills the frontier labs. It relocates them. The volume runs on the open-weight genetic pool; the frontier becomes the premium specialist. And the players who confused owning the biggest model and cluster with owning the moat just posted the proof.
4. Meta-Harness — Stanford formalises the heresy
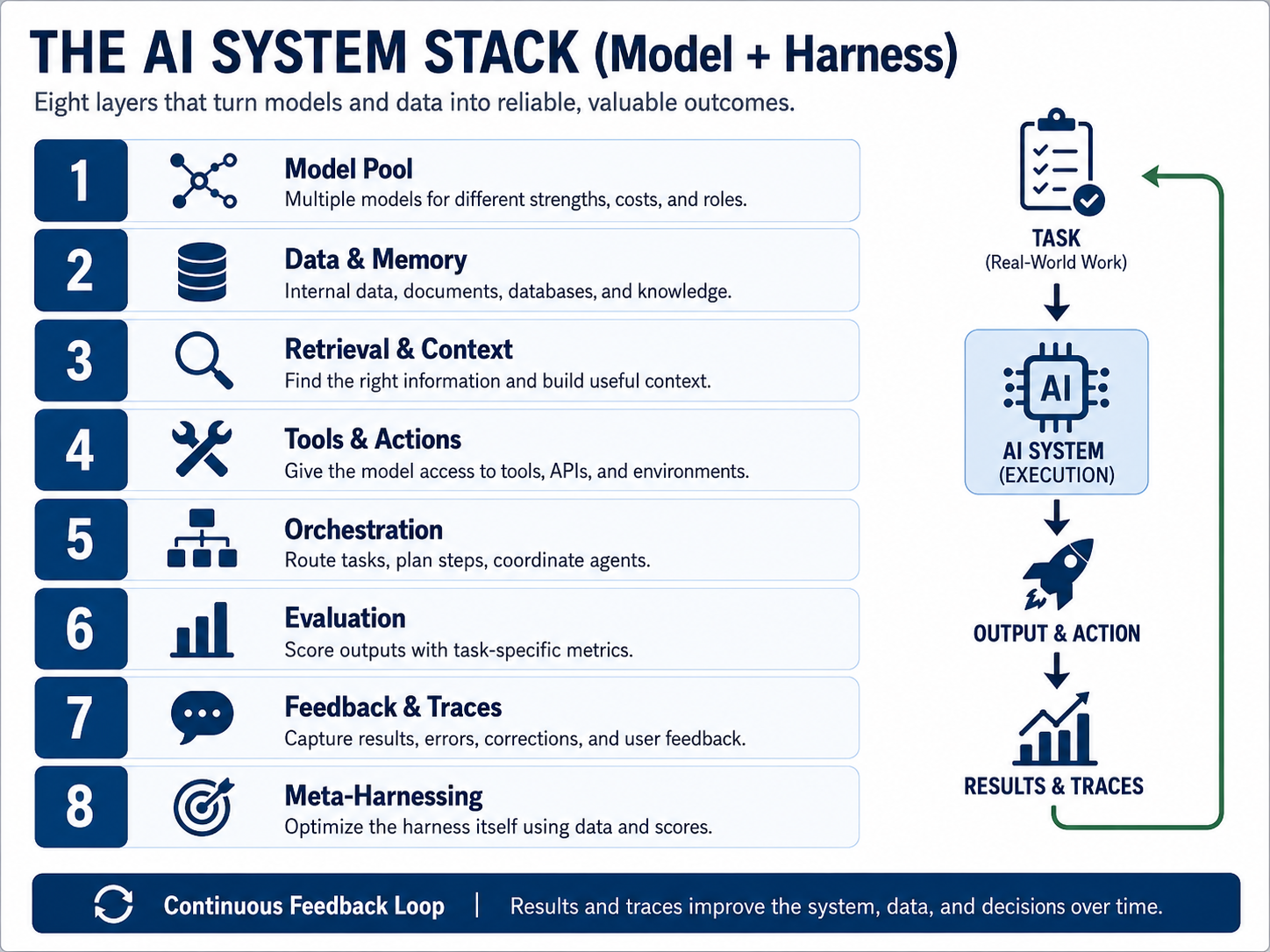
The intuition needs a mechanism, and in March 2026 it got one. “Meta-Harness: End-to-End Optimization of Model Harnesses” (Lee, Nair, Zhang, Lee, Khattab, Finn — Stanford IRIS Lab; arXiv 2603.28052, 30 March 2026) makes a claim that reads like our thesis in academic register: the performance of an LLM system depends not only on model weights, but on the harness — the code that decides what information to store, retrieve and present to the model.
That reframing changes everything. If the harness governs what the model sees, remembers and retrieves, then the output is not a property of the model. It is a property of the model-plus-harness system.
Meta-Harness then goes one level further: it builds an outer-loop agentic system that searches over harness code, giving a coding-agent proposer full filesystem access to the source, scores and execution traces of every prior candidate (grep and cat, not one compressed prompt). The harness itself becomes an object of optimisation. The results are not cosmetic:
- +7.7 points over a state-of-the-art context-management system on online text classification, while using 4× fewer context tokens;
- +4.7 points average accuracy on 200 IMO-level problems across five held-out models from a single discovered retrieval harness;
- first place on TerminalBench-2 agentic coding, past the best hand-engineered baselines.
The investment conclusion is not “one paper solved enterprise AI.” It is sharper and more dangerous: performance is moving from model scale alone to system architecture around the model. If a better harness makes a cheaper or weaker model win the actual task, the economic centre of gravity shifts off the weights. And the paper's own forward look — co-evolving harnesses with weights, extending the loop to modular orchestration — is precisely the breeding machine this Heresy is about.
5. What a harness is, in plain language
A harness is the operating environment around the model — the layer that turns a text generator into a production system. It includes the system prompts, instruction policies, memory, retrieval, context selection, tool and database and browser access, planning loops, self-checking, multi-agent coordination, routing logic, evaluation, fallback models, human-approval steps, cost controls, logging, observability, permissions and feedback capture.
The model is the engine. The harness is the vehicle, the road system, the dashboard, the braking system and the maintenance process. A stronger engine in a poor vehicle loses to a weaker engine in a better-designed system. This is why benchmarks mislead investors: a benchmark measures a model under benchmark conditions, while enterprise value is produced under workflow conditions. The gap between those two is where harnessing lives — and where margin will accrue.
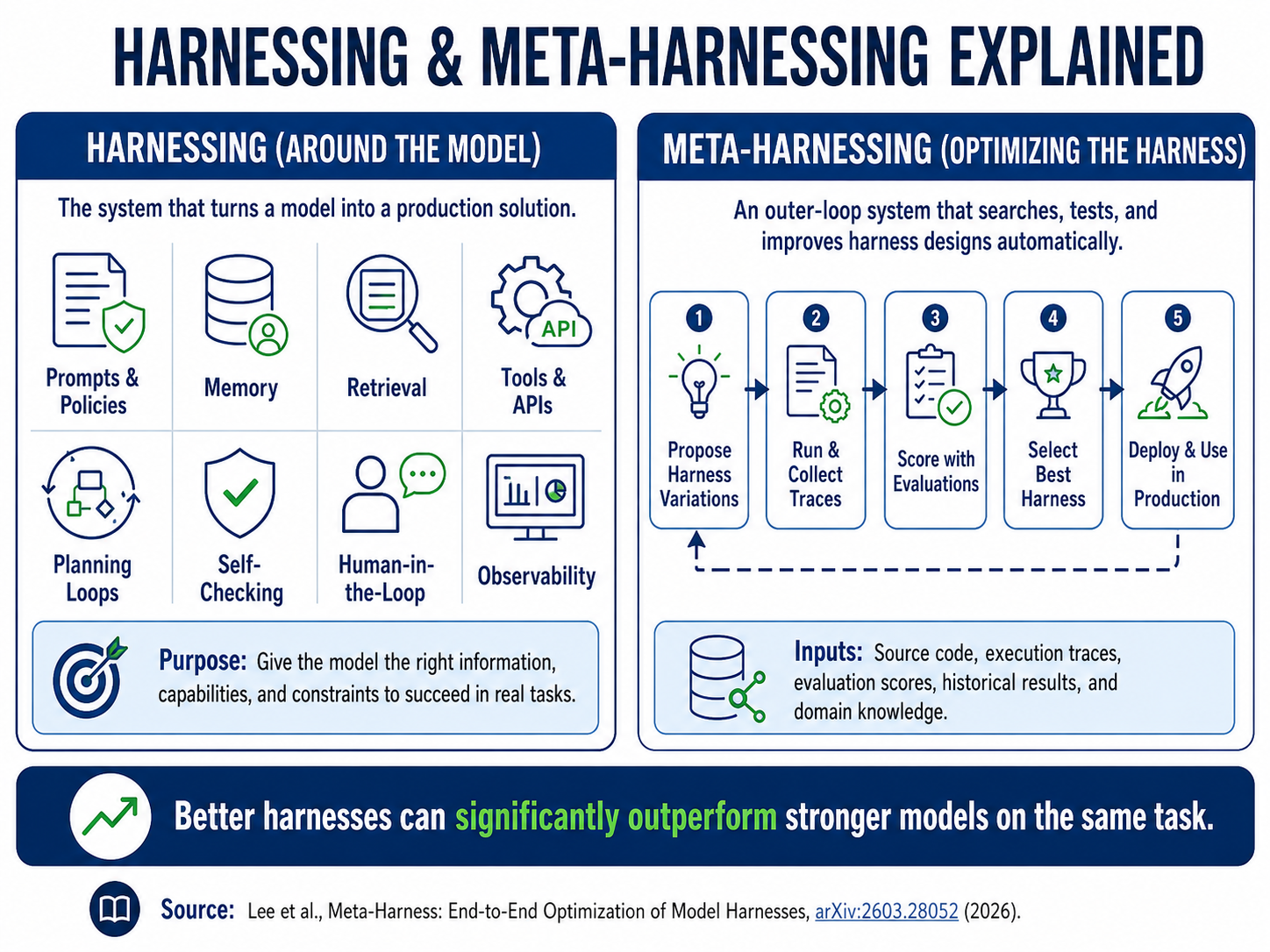
6. Meta-harnessing — the recursion that turns adoption into breeding
Harnessing means designing the system around the model. Meta-harnessing means optimising the harness itself. That recursion is the whole game, and adoption is climbing its rungs in order:
- choose a model → write prompts → deploy a chatbot;
- wrap it in retrieval and tools → build agents;
- evaluate the agent → improve prompts, memory, retrieval, tool use, workflow;
- build a system that searches over harness designs and improves the workflow automatically.
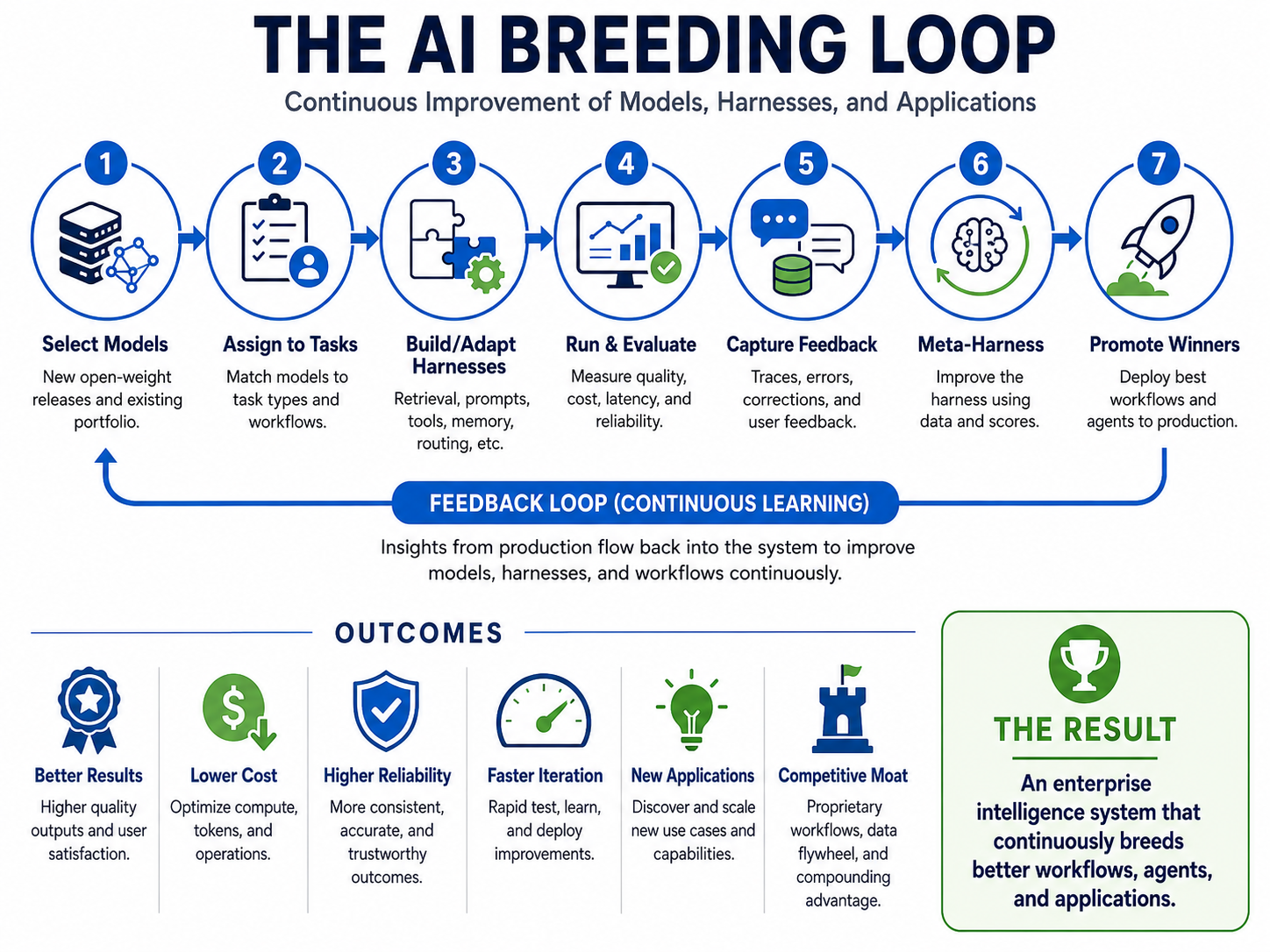
At rung four the enterprise no longer merely uses AI. It uses AI to improve the system that uses AI. And that is best understood not as engineering but as breeding. You hold a population of models, prompts, retrieval methods, memory structures, tool configurations, agent loops and eval methods. You test, score, mutate, recombine, keep the winners, discard the losers, promote the winners into production — and then use production traces to seed the next generation. The company becomes an evolutionary system for applications.
7. Open weights are the genetic pool
If open-weight models keep improving, the enterprise receives a continuous stream of raw genetic material. Each new model is tested against proprietary harnesses and task suites: better for coding, or classification, or retrieval, or reasoning, or German-language compliance, or medical documentation? Cheaper at equal quality? Faster at acceptable quality? Lower hallucination in this domain? Fit for a planner, an executor or a judge?
The enterprise does not need one perfect model. It needs a model portfolio — a strong generalist, a cheap high-volume workhorse, a coding model, a reasoning model, a classifier, a retriever, a local sovereign model, and a frontier API kept in reserve. The router becomes as important as the model; the eval suite as important as the benchmark; the harness as important as the weights.
One live complication, straight from §3: the genetic pool is increasingly Chinese. With Llama faltering, the strongest open weights are drifting east — which turns “own your own weights” from a convenience into a governance argument. An enterprise breeding on borrowed foreign weights it neither controls nor can guarantee raises exactly the residency, auditability and dependency questions that push serious operators toward controlling the model, not merely downloading whoever is briefly ahead. The pool matters; owning your position in it matters more.
8. The intelligence control plane
Stack the layers and the picture stops looking like “one model to rule them all” and starts looking like a modular intelligence factory: a model pool (open, fine-tuned, distilled, plus selective closed APIs); a data and memory layer bound to internal documents, tickets, code and decisions; retrieval and context selection deciding what the model sees; a tool and action space that makes the agent operational; orchestration that decomposes tasks and routes them; evaluation that scores real workflow outcomes, not benchmarks; trace and feedback capture turning every run into training material; and, on top, meta-harnessing that proposes, tests and keeps harness improvements.
The enterprise of 2028 does not ask “which model do we use?” It asks: which intelligence configuration wins this task under our constraints? That question — asked continuously, answered automatically — is the architecture of owned intelligence.
9. Who wins, who loses
Winners are whoever owns the layers where system performance compounds: model-router and orchestration layers (the dispatch layer of enterprise intelligence); evaluation and observability (the measurement system of production AI — and, per §15, the earliest leading indicator of the whole shift); data and retrieval platforms (context quality is output quality); AgentOps and workflow governance; security and identity (agents need permissions and audit trails); inference infrastructure (not all demand flows through frontier APIs); vertical application builders with deep workflow ownership; and — most underappreciated — incumbents with proprietary workflow data who can reorganise around harnessed intelligence. The best AI application company in a vertical may already be the incumbent.
Losers are those whose valuation assumes model access remains scarce: pure closed-model API providers if they slide from platform to premium supplier; thin wrappers with no data, workflow or eval loop; generic copilots without workflow depth; enterprises that outsource the learning loop and get outputs without compounding; and software companies without control points over data, workflow, identity or distribution.
10. The market map — who is assembling the owned-intelligence stack
This is not a forecast about a market that might form. The “own your own weights plus harnessing” market is already emerging — but it is fragmented, and no single platform owns it. The closest full-stack candidates each approach the problem from a different starting point: Databricks Mosaic AI from data and the ML lifecycle (fine-tuning, serving, MLflow evaluation, vector search, governance, agent-building on governed enterprise data); IBM watsonx / Granite with Red Hat AI from open enterprise models and governance — Apache-licensed Granite models, fine-tuning through RHEL AI and InstructLab, watsonx governance around them, aimed squarely at regulated industries; NVIDIA NeMo / NIM from AI infrastructure and deployment — synthetic data, fine-tuning, evaluation, guardrails, inference and observability as one packaged stack; Hugging Face Enterprise from the open-model ecosystem — the neutral marketplace and deployment layer for the genetic pool itself; and Palantir AIP from ontology, operational workflow and agent governance — not “own your weights” in the strict sense (it is model-agnostic), but conceptually the closest public-company example of the harness-first thesis, down to AIP Evals creating test cases, comparing performance across LLMs and examining variance across executions.
Around these platforms sits a fast-growing tooling layer: LangChain/LangGraph, LlamaIndex, DSPy, Semantic Kernel, AutoGen, CrewAI and NeMo Guardrails on the harness and orchestration side — DSPy especially interesting because it treats prompts and pipelines as optimisable programs, which is the meta-harnessing logic in miniature. And below the platforms sits the service layer, where the practical market may grow fastest: most enterprises will not assemble this stack themselves. Accenture, Deloitte, BCG X, Capgemini, EPAM and their peers will implement open-weight-plus-private-harness architectures for large enterprises; the clouds (AWS, Azure, Google Cloud, Oracle) will bundle private deployment, model catalogues, fine-tuning, vector stores, agents, evals and guardrails into their platforms; and the data platforms (Snowflake, Databricks, MongoDB, Elastic, Confluent) matter because the harness needs data, memory, retrieval, governance and workflow context.
The research frontier already runs ahead of the products. EnterpriseLab, a 2026 paper describing a full-stack platform for enterprise agents — enterprise tools unified via Model Context Protocol, automated trajectory synthesis for training data, integrated training pipelines, continuous evaluation — reports that 8B-parameter models trained in this setup can match GPT-4o performance on complex enterprise workflows while cutting inference cost 8–10×. That is the thesis in experimental form: a small controlled model plus a strong enterprise harness becomes economically superior for specific workflows. Parallel work on multi-model orchestration for self-hosted LLMs reports higher success rates at lower latency and GPU cost versus static deployment — orchestration itself becoming a performance layer.
The category exists, but it is not yet consolidated. The winner may be the platform that combines open-model selection, private deployment, retrieval, orchestration, evals, governance, feedback capture and continuous harness improvement into one enterprise control plane. That fragmentation is the opportunity.
11. Systems of record → systems of intelligence
The first SaaS era produced systems of record — Salesforce for customers, Workday for people, ServiceNow for workflow, Snowflake for data, Okta for identity. The application owned the database and the workflow, and that ownership was the moat.
The AI era produces systems of intelligence. But the system of intelligence is not one model. It is the orchestration layer that coordinates many models and agents around enterprise workflows — and it owns the workflow, the evals, the task traces, the memory, the agent permissions, the routing policy and the harness-improvement loop. Agent orchestration may become to AI what the system of record was to SaaS.
And the real moat underneath it is not “data” in the loose sense. It is proprietary task distribution — knowing what work actually occurs, how often, with what inputs, exceptions, corrections, approvals and definitions of success. A static PDF library is not a moat. The captured work itself is. That is what the harness learns from, and it is the one thing a frontier API cannot download.
12. Cost beats benchmarks; sovereignty is only the visible part
Benchmarks chase maximum capability; production chases cost-adjusted capability. A model that is 5% better but 10× more expensive is wrong for most tasks, because enterprise AI is not one task — it is millions of repeated ones, where cost differences are architecture differences. A cheap local model classifies, a mid-size open model summarises, a specialist model writes code, an internal reasoning model analyses, and the frontier API is reserved for the hard exception. The correct question is never “which model is strongest?” but “what is the cheapest system that reliably achieves the required outcome?” — an engineering question, not a benchmark one.
Sovereignty is the loud argument for owning weights — governments, banks, defence, healthcare and industry wanting residency, auditability and vendor independence. It is real, but it is the defensive half. The offensive half is performance compounding: control the model and the harness, and you can specialise to your own workflows, capture your own corrections, tune your own cost and latency, and build your own evals. Sovereignty is necessary; compounding is where the alpha is.
13. The Closelook frame — where this sits
Regular readers know the map. Stage 1 is the AI capex cycle — the Rubin Build-Out layer of silicon, memory, packaging, power and cooling. Stage 2 is the AI opex cycle — the agentic-infrastructure layer of inference, routing, orchestration, observability, memory, retrieval, security and identity, billed by consumption rather than seat. Stage 3 is applications — vertical agents and AI-native software. These recur as waves across successive accelerator generations, running through at least 2030.
This Heresy lives at the bridge between Stage 2 and Stage 3 — the harness. It tells you why the three-index framework is built the way it is: the Rubin Build-Out tracks the physical layer (and §3 is a reminder that owning that layer is not the same as owning the moat); the Agentic Ecosystem index tracks exactly the control-plane layers — orchestration, evals, observability, retrieval, security — where §9 says the margin migrates; and the Agentic Winners read the rotation as it happens. Through the ABR (Agent Beneficiary Ratio) lens, the names that screen best are those whose value rises with harnessed intelligence rather than falling as model access commoditises. And the Generation Rotation logic holds: the sectors are permanent, the leadership rotates — from the build-out, to the operating layer, to the application layer that harnessing unlocks.
The heresy for portfolio construction: the frontier model provider may not capture most of the long-term margin in this stack. AI infrastructure should not be reduced to chips, and AI applications should not be reduced to chatbots. The bridge between them is the harness — and that is where the compounding, and the ABR, point. (As always: reference-portfolio logic, skin in the game, publishing and money management kept separate — not personalised advice.)
14. The Closelook mirror
This is not an abstraction for us. A financial-media operation used to need scale in headcount — analysts, chart producers, data engineers, editors, newsletter operators, SEO specialists, distribution teams. In the old world, scale meant bodies. In the new world, scale means harness quality.
A small team can stand up a model portfolio around market-data ingestion, chart and index construction, relative-strength and divergence scanning, earnings and macro summarisation, drafting, visual production, AEO/SEO formatting, translation and alerting. But the moat is never “we use AI” — everyone uses AI. The moat is that the harness is built around our own worldview: our indices, taxonomies, signals, editorial voice, visual standards and reader relationships. The model does not replace the thesis; the model must be harnessed by the thesis. That sentence is the entire Closelook operating principle, stated in one line.
15. The investor's watchlist — and the one leading indicator
Watch for the shift from model use to harnessed intelligence across the familiar tells: whether open-weight models become good enough for more production workflows (not whether they top a leaderboard); inference-cost collapse making high-volume agentic work viable; model-routing adoption (every router weakens single-model ownership); agent observability for long-horizon tasks; enterprise fine-tuning and distillation as signs companies are adapting, not just renting; sovereign deployments in regulated sectors; workflow-native applications that own recurring task distributions; the decisive late tell of frontier API usage sliding from default engine to premium fallback, judge and teacher, and whether the frontier's revenue-per-token premium is holding or compressing as harnessing matures (the single number that tells you which side of the 20/80 glide you are on). And, per §3, keep watching the sellers of compute: a landlord that owns a frontier cluster but rents it out is telling you its model bet failed, not that the world has surplus silicon.
But the earliest of these — the leading indicator that precedes every other — is the growth of eval infrastructure.
Eval infrastructure is the measurement and quality-control layer of an AI system: the task test sets, the scoring criteria and rubrics, the model-and-harness comparison methods, the production monitors and the human-feedback loops that determine whether a given model, prompt, retrieval system, agent or harness is actually improving. It is not one benchmark. It is the full apparatus for testing, scoring, comparing, monitoring and improving the whole stack — quality control for AI production. Without it a company is guessing whether model A beats model B, whether a new harness beats the old one, whether a quiet model upgrade just broke a working workflow. With it, those become measured facts — accuracy, citation quality, hallucination rate, task-completion rate, cost and latency, scored against the work that actually matters rather than a public leaderboard.
Why it leads: everything else in this Heresy is downstream of measurement. The model portfolio (§7) is only exploitable if you can score which model wins which task under your cost, latency, risk and compliance constraints. Harnessing and meta-harnessing (§5–6) are impossible without it — a harness can only be improved if the system can prove the new one beats the old. The breeding loop turns on exactly this pivot: build → run → score → compare → keep the winner → capture failures → improve; remove the score and the loop cannot select, so it cannot compound. A company therefore cannot route, cannot distil, cannot harness and cannot own its compounding layer until it can measure — which is why rising spend on evaluation, observability and trace capture shows up first, well before the frontier's revenue share ever begins to compress. It is the earliest balance-sheet evidence that an enterprise is crossing from renting intelligence to owning it. Watch the measurement layer, and you are watching the thesis form.
And this is no longer hypothetical. Eval infrastructure is already a product category — early, fragmented, and without one agreed name, but recognisably formed across four layers:
| Layer | Representative names |
|---|---|
| Horizontal eval + observability platforms | LangSmith · Braintrust · Arize Phoenix · Langfuse · Weights & Biases Weave |
| Developer-native eval frameworks (CI-style testing) | DeepEval · Ragas · Promptfoo |
| Hallucination / safety / trust specialists | Patronus AI · Galileo · Confident AI |
| Agent tracing, routing + feedback loops | Helicone · Portkey · Opik · Humanloop · HoneyHive |
Above them, every platform owner — OpenAI, Anthropic, Google, AWS, Azure, Databricks, Snowflake, Hugging Face — has an incentive to bundle evals next to model selection, deployment, routing, guardrails and monitoring. The strategic question is whether eval infrastructure becomes an independent control plane for enterprise AI or gets absorbed into the model and cloud platforms. One small tell: OpenAI is winding down its hosted Evals platform (read-only from end-October 2026) while keeping the open-source framework — the neutral scoreboard may not end up living inside the labs. And below them, the classic observability and security incumbents — Datadog, Dynatrace, New Relic, Elastic, Splunk/Cisco, Cloudflare, plus the identity and security stacks (Okta, Palo Alto, CrowdStrike, Zscaler) — extend naturally into agent monitoring, because AI agents create a new class of traces: prompts, tool calls, model outputs, retrieval context, user corrections, hallucination flags and autonomous actions. Not the same as classical observability — but the buyer, the budget and the architecture overlap.
The investor split falls out cleanly. The pure-play exposure is mostly private for now — LangChain/LangSmith, Braintrust, Arize, Langfuse, Patronus AI, Galileo, Confident AI, Humanloop, HoneyHive, Helicone, Portkey, plus Hugging Face, LlamaIndex, Modal, Together AI, Fireworks AI and Anyscale in the surrounding stack. The public-market exposure is adjacency: Datadog, Dynatrace, Elastic, Cloudflare, Snowflake, GitLab, ServiceNow, Atlassian, Cisco/Splunk, Microsoft, Alphabet, Amazon — and, from §10, IBM, NVIDIA and Palantir, with Databricks if it lists. The most important point: eval infrastructure is not a nice-to-have. It becomes mandatory once agents move from demo to production, because production AI needs exactly what production software needed before it — testing, tracing, monitoring, regression detection, quality control and governance.
16. The bear case, kept honest
A good heresy states its own refutation. The frontier labs may stay so far ahead that open-weight systems never catch up on economically important tasks; APIs may get cheaper, faster and more customisable; and the labs may absorb the harness layer themselves — offering private deployments, fine-tuning, evals, memory, orchestration and agent platforms — so the model provider stays the platform. Enterprises may also simply lack the skill to build harnesses and prefer integrated managed platforms, in which case value accrues to harnessing-as-a-service rather than to owned weights. And open-weight deployment may be constrained by safety, liability and regulation in some sectors.
So the thesis is not guaranteed. The precise, defensible version is narrower and stronger than “own your weights and win”: companies that can combine open-weight model selection, proprietary data, workflow control, evals, orchestration and meta-harnessing may build superior systems to companies that merely consume frontier APIs. The market should not assume every company can own its own weights effectively. But the direction is real, because performance has become a system property — and once it is, raw model strength alone cannot explain value capture.
17. The heresy, sharpened
Consensus says the strongest model wins. The heresy says the strongest learning system wins.
Consensus says enterprises will rent intelligence from frontier labs. The heresy says they will rent some frontier capability but try to own the compounding layer.
Consensus says open models are a cheaper substitute. The heresy says open weights are the genetic pool from which enterprises breed proprietary workflows.
Consensus says the model is the moat. The heresy says the moat is the harness plus the proprietary task distribution.
The AI market began by asking who has the best model, then who has enough compute, then who can monetise inference. The better question now is: who owns the learning system around the model? That system includes the weights — but it does not end there. It includes harnesses, evals, traces, workflows, memory, retrieval, tools, routing, feedback, domain data, and the meta-harness that improves them.
The model is becoming an ingredient. The harness is becoming the recipe. The meta-harness is becoming the chef that improves the recipe. Two of the largest model-and-compute owners on Earth just became landlords of their own idle clusters — the clearest signal we have that owning the model was never the moat.
Open weights provide the genetic pool. Orchestration selects the right organism. Harnessing adapts it to the environment. Meta-harnessing improves the adaptation itself.
The frontier model may still be stronger in the abstract. The enterprise that owns the harness may win in reality.
Heresies is a series of contrarian investment theses; this is Heresy XI, following Heresy X — The Numerator Regime, Heresy IX — The Constraint Relay and Heresy VIII — Memory Is the New Compute. Sources: Lee, Nair, Zhang, Lee, Khattab, Finn — “Meta-Harness: End-to-End Optimization of Model Harnesses” (Stanford IRIS Lab, arXiv 2603.28052, 30 Mar 2026); SpaceX SEC filings and public reporting on the Anthropic Colossus 1 lease (~$1.25bn/month, ~220k GPUs, 300MW, through 2029) and the Google compute agreement (~$920m/month, ~110k GPUs, “bridge capacity” for Gemini Enterprise); the reported internal xAI utilization memo (~11% MFU); Bloomberg / CNBC reporting on “Meta Compute” and hosted Muse Spark (1 Jul 2026); the Ramp AI Index (enterprise AI-spend concentration); EnterpriseLab (2026) on 8B models matching GPT-4o on enterprise workflows at 8–10× lower inference cost. Named companies throughout are exemplars of stack layers, not a recommendation list. Reference-portfolio commentary, not individual investment advice — we hold skin in the game on the themes we write about, and publishing and money management remain separate. Figures reflect public reporting current to early July 2026.