Heresy · 09:00 CET
Memory Is the New Compute — Closelook Heresy VIII
The market still prices memory through the old DRAM cycle. But HBM4, HBM4E and HBM5 are becoming logic-rich extensions of the accelerator — and by the time we reach Feynman, memory may rival the GPU itself in strategic importance.

The GPU stays the engine. But the further we go into Rubin and Feynman, the less memory even behaves like memory — and the more it behaves like a second processor bolted to the first. The market has not re-rated that idea. This is the heresy.
The heresy: The market still prices memory as a cyclical commodity you trade — buy the DRAM bottom, sell the spike. In the agentic era, memory is becoming a logic-rich extension of the accelerator, upgraded every generation, and by Feynman it may rival the GPU itself in strategic importance. HBM4 is not faster PC RAM — it is an AI architecture layer. The full re-rating of that idea is not yet inside the investment community.
Every Heresy starts the same way: a consensus model that used to work, and a structural change that has quietly invalidated it. The consensus model here is the DRAM cycle. For thirty years it was reliable enough to trade on. The structural change is that AI factories don’t buy memory the way PCs did — and the deeper you go into Rubin and Feynman, the less memory even behaves like memory.
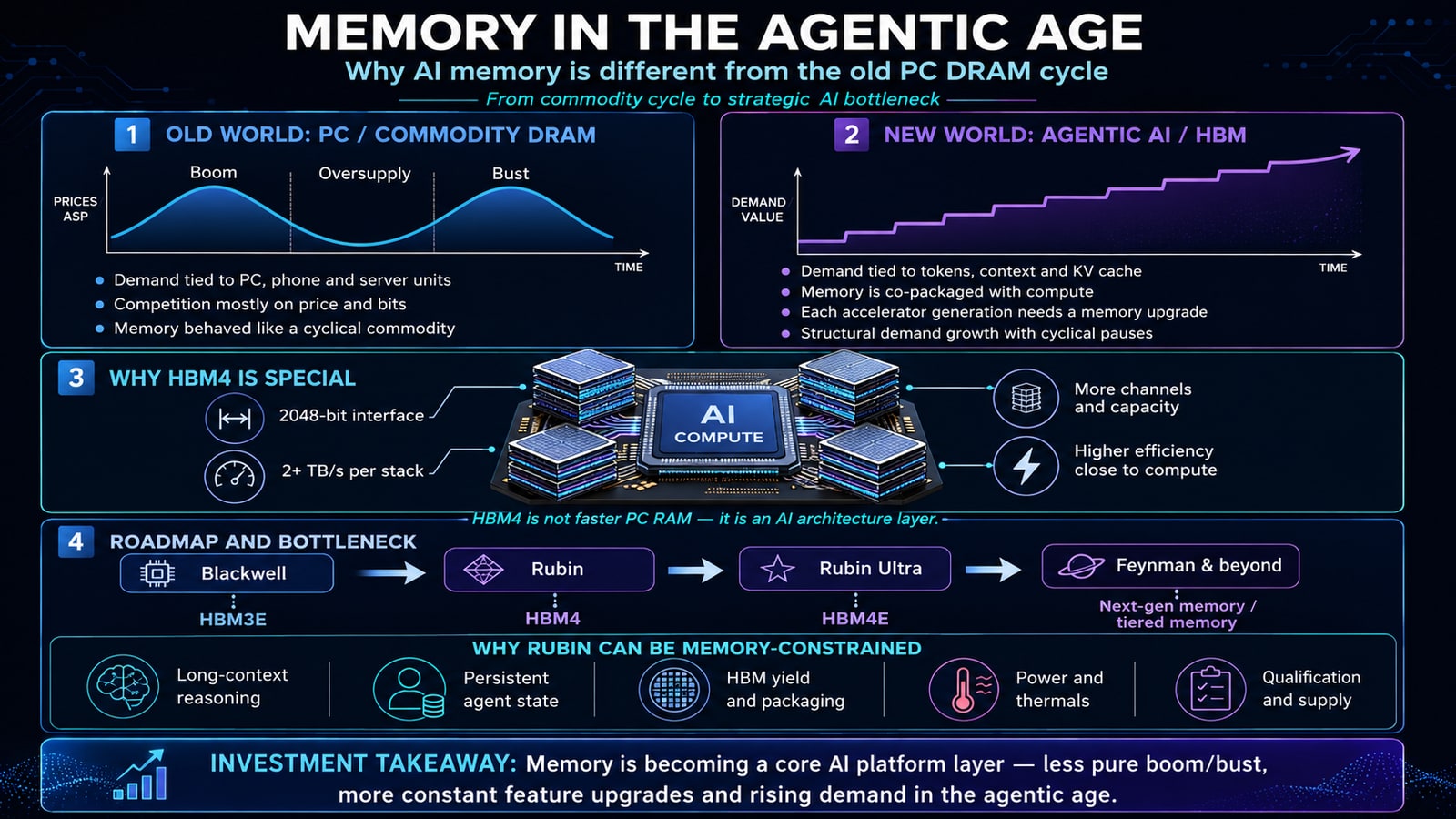
1. The old model: memory as a capacity commodity
In the PC and smartphone era, the demand question was simple and the answer was a number: how many gigabytes does the device need? Demand tracked unit shipments and software bloat. The product was broadly interchangeable — Samsung, Micron and SK hynix modules competed mainly on price, capacity, timing and supply. That made the business brutally cyclical, with a shape everyone learned: oversupply → price collapse → capex cuts → shortage → spike → reset.
The trade that fell out of that was equally simple: buy when DRAM prices bottom, sell when pricing peaks. It worked because the bottleneck was always solvable — add capacity, supply catches up, prices crash, cycle resets. Memory was supporting hardware: a closet where the computer kept things while it worked. More memory meant a bigger closet. Useful, but passive.
I am not going to tell you the cycle is dead. Inventory cycles, capex cycles, pricing air-pockets, customer concentration and China/export risk are all real and can still produce sharp corrections. What I am telling you is that the baseline demand curve underneath the cycle has changed — the floor is rising, and the curve runs far past where the old PC/server model said it should.
2. The new model: memory as the working surface of intelligence
In the PC age, memory was a closet — you stored things there while the machine worked, pulled out a folder, used it, put it back. Passive. In the agentic age, memory becomes the kitchen counter of intelligence — the active surface where context, tools, documents, reasoning steps and intermediate outputs are constantly moved, combined and reused. A single chatbot answer can be stateless. An agentic workflow is stateful: it keeps files, tool outputs, browsing steps, code execution, user preferences, prior attempts, database results and intermediate plans alive while it runs.
That is the morphing in one line: old memory stored the work; new memory is where the work happens. And it changes the demand drivers entirely:
| Driver | Old PC era | Agentic AI era |
|---|---|---|
| Main demand unit | PCs, phones, servers | AI factories, GPUs, agents |
| Key metric | GB per device | Bandwidth, capacity, latency, watts/token |
| Product | Commodity DRAM/NAND | HBM, HBM4E, CXL memory, fast SSDs |
| Upgrade reason | OS/app needs | Model scale, inference scale, context scale |
| Customer relationship | Broad OEM market | Deep qualification with NVIDIA/AMD/hyperscalers |
| Scarcity | Wafer capacity | Wafer + packaging + yield + power + qualification |
When the demand unit moves from devices to agents, and the key metric moves from gigabytes to watts per token, you are no longer in the same business. You are selling jet engines to aircraft makers, not steel to carmakers.
3. What makes HBM4 special
HBM4 attacks the AI “memory wall” from several directions at once. It is not faster PC RAM bolted onto a bigger chip — it is a high-speed memory engine co-designed into the accelerator package, connected through very wide interfaces, TSVs, base dies and interposers.
- Bandwidth. JEDEC specifies up to 2 TB/s per stack; Micron quotes its commercial HBM4 at over 2.8 TB/s, explicitly targeting training, inference latency and faster KV-cache access.
- A wider interface. HBM4 moves to a 2,048-bit interface — double the width of prior generations — which is much of why it can actually feed a Rubin-class accelerator.
- More parallelism. Independent channels double from 16 to 32.
- Energy efficiency. Every bit moved costs power, and AI factories are increasingly limited by power and cooling, not chip availability. Bandwidth-per-watt is now first-order.
- Capacity scaling. 12-high and 16-high stacks put more memory next to the GPU — exactly what large models, Mixture-of-Experts, long context and inference serving demand.
The single most important word there is KV cache. Long-context inference is not just compute; it is capacity plus bandwidth plus latency. KV cache scales with context length and concurrent users, and if you have to recompute it, cost rises exponentially. Efficient KV-cache management has quietly become a determinant of inference economics. That is a memory problem.
4. Why HBM4 is the Rubin bottleneck
Rubin is not a GPU; it is a rack-scale system — Vera CPU, Rubin GPU, NVLink, networking, DPU, cooling and software co-designed together, built around HBM4. The logic is simple: Rubin’s compute engines only deliver their promised performance if memory can keep them fed. Extreme FP4 compute behind an undersized memory pipe is a Formula 1 engine with a fuel line too narrow.
And the bottleneck is not just the DRAM dies. It is the whole stack of hard things around them: HBM yield (stacking many dies vertically is difficult), base-die and logic integration, advanced packaging (GPU, stacks, interposer, substrate and thermal solution must all work together), thermals (HBM sits beside extremely hot accelerators), qualification (NVIDIA cannot swap suppliers overnight), and capacity allocation (every wafer moved to HBM tightens conventional DRAM supply too). This is why the investment story inverts. In PCs, memory suppliers fought each other inside a commodity cycle. In Rubin-class systems, qualified HBM suppliers become gatekeepers of the AI accelerator ramp — a different bargaining position and a different margin structure.
5. The roadmap is the thesis: HBM4 → HBM4E → HBM5
The roadmap is not “HBM3E, then pause.” It is a staircase, and each step raises memory intensity:
HBM3E → HBM4 → HBM4E → HBM5 / custom HBM / processing-in-memory / CXL / tiered & disaggregated memory.
The crucial detail is what changes across the staircase. HBM4 remains relatively standard. HBM4E and HBM5 are expected to move toward custom HBM — customer-specific designs, power optimization, and far more capable base logic dies. TrendForce (citing The Elec) frames it exactly this way: HBM4 standard, HBM4E and HBM5 increasingly custom. SK hynix has previewed HBM4E up to 16 Gbps per pin; Rubin Ultra reporting points to very large HBM4E configurations — including claims of 1 TB of HBM4E per accelerator package in Rubin Ultra trays.
Hold onto this. That customization — a capable, accelerator-specific logic die at the base of the stack — is the hinge of this entire Heresy. It is the moment memory stops being storage and starts becoming a co-processor.
6. From component to co-processor: why memory rivals the GPU
Here is the step the consensus underweights — and the heart of the twist.
In the training era, the market focused on the accelerator: more tensor cores, more FLOPS. The GPU defined the ceiling. But agentic, long-context, multimodal inference stresses the whole platform — compute, interconnect, bandwidth, capacity, latency, power and utilization — and inefficiencies compound across trillions of tokens. So the GPU is still the star, but memory becomes the difference between theoretical GPU performance and delivered AI-factory performance.
In the training era, GPUs defined the ceiling. In the agentic inference era, memory defines how much of that ceiling you can actually use.
Now layer in the custom-logic shift from Section 5. The HBM stack contains a base logic die. Once that die becomes more capable and accelerator-specific — precisely the HBM4E/HBM5 direction — memory stops being passive storage. It starts absorbing functions: address translation, compression/decompression, data-movement control, KV-cache management, prefetching, error handling, and near-memory compute. The memory stack becomes an extension of the accelerator architecture itself.
The moment HBM carries a capable, accelerator-specific logic die, the question changes. A passive component does not rival the processor; a co-processor does. That is what HBM4E and HBM5 are quietly becoming — and it is why, by Feynman, the memory subsystem may matter to delivered performance as much as the GPU that sits beside it.
This is not hand-waving. A 2026 research line on HBM-PIM for LLM inference argues serving is now limited by the KV cache — each new token rereads prior KV state during decode, making attention a bandwidth- and capacity-heavy memory task — and proposes using HBM4’s logic-die substrate for stack-local control and near-memory functions, improving token throughput and cutting energy in simulation. That is the bridge from memory chips to memory intelligence.
The analogy: a GPU is the chef. Memory used to be the pantry. In the agentic age memory becomes the kitchen line — the active surface where ingredients, orders, timing, partly-cooked dishes and chef-to-chef communication are constantly moving. A great chef is useless if the line is too narrow, too slow, too hot or poorly organized. The GPU still does the cooking; memory determines how many meals the restaurant serves per hour.
Mapped to the roadmap, the implication sharpens generation by generation — until at the end of it, memory and the GPU are no longer in different weight classes:
| Generation | Memory role | Strategic implication |
|---|---|---|
| Blackwell / Blackwell Ultra | HBM3E as high-bandwidth fuel | GPU still dominates the story |
| Rubin | HBM4 becomes platform-critical | Memory starts defining delivered performance |
| Rubin Ultra | HBM4E adds density, bandwidth, customization | Memory becomes a co-designed subsystem |
| Feynman | HBM5 / next-gen, more custom and logic-rich | Memory may rival GPU architecture in importance |
The further into agentic AI we go, the more system value depends on tokens per watt, tokens per dollar, context per user, latency per workflow, and utilization per rack. Those are not pure GPU metrics. They are memory-system metrics. GPUs create the intelligence; memory determines how much of it can be delivered.
7. Who controls the memory wall: the leader, not yet the certainty
If memory is becoming a logic-rich co-processor, the investable question changes from who makes the GPU? to who controls the memory wall? Today, the cleanest answer is SK hynix — best positioned, not guaranteed winner. The reason isn’t only that SK hynix is strong in HBM now. It’s that the next stages reward exactly what it has already built: early HBM execution, deep NVIDIA/customer qualification, high-stack manufacturing, and tight links to advanced packaging. In AI memory, qualification momentum compounds — once you are designed into NVIDIA-class platforms, switching is not as easy as buying commodity DRAM elsewhere.
- Share leadership (point-in-time, estimates vary). Tom’s Hardware recently cited SK hynix at 61% HBM share, versus 21% Micron and 17% Samsung; Mordor Intelligence projects SK hynix holding >60% in 2026. Treat these as snapshots, not constants.
- Carrying the lead into HBM4. SK hynix’s own outlook cited a UBS estimate of ~70% HBM4 share for NVIDIA’s Rubin platform in 2026 — an analyst figure, not confirmed procurement, but it suggests the lead isn’t purely backward-looking.
- The HBM4E/HBM5 game is execution, not just capacity. As value shifts to logic-die design, reporting indicates Samsung leans on in-house 4nm logic dies while SK hynix is considering TSMC 3nm for HBM4E logic — a potential edge if execution holds. SK hynix has also reportedly pulled forward HBM4E sample timing for key customers.
But Samsung and Micron cannot be written off. Micron is increasingly credible in HBM4 (>2.8 TB/s, aimed squarely at next-gen AI), and matters strategically because NVIDIA and US AI infrastructure need diversified, qualified supply. Samsung’s structural advantage is combining memory, foundry, advanced packaging and logic under one roof — and as the base logic die becomes more important, that integration could become very competitive in custom HBM4E/HBM5 if it fixes yield and execution. So the honest stance: SK hynix has the strongest current momentum; HBM4E/HBM5 will be more contested precisely because the prize is bigger.
8. How big can this get: TAM / SAM / SOM
The bridge from “SK hynix leads” to “how big can this become” is a sizing frame. The relevant TAM is not all DRAM — too wide. It is AI high-performance memory for accelerators and AI factories.
| Market layer | Definition | Rough TAM framing |
|---|---|---|
| Narrow TAM | HBM only: HBM3E/4/4E/5 | Tens of billions by 2030 |
| Expanded TAM | HBM + custom HBM + logic-rich memory | Larger than standard HBM — value shifts from bits to architecture |
| AI memory platform TAM | HBM + tiered memory + near-memory logic + AI server memory hierarchy | Broadest long-term opportunity |
The direction is clear even though estimates vary. TrendForce-cited figures (via Chosun Biz) put HBM demand growth near +77% in 2026 and +68% in 2027, with HBM4E reaching ~40% of HBM demand by 2027. SK hynix has talked about an HBM market compounding ~30% annually toward tens of billions by 2030, with some analyst estimates as high as ~$98B. The punchline: the HBM TAM is no longer just a memory-chip TAM — it is becoming an AI-throughput TAM.
SK hynix’s SAM is narrower but still very large: premium HBM4E/HBM5 and custom HBM for NVIDIA, hyperscaler ASICs, AMD, and next-gen platforms — the highest-value layer, not low-end memory. For SOM, be disciplined. This is a scenario framework, not a forecast:
| Scenario | HBM market by 2030 | SK hynix share | HBM revenue opportunity |
|---|---|---|---|
| Bear | $40B | 35% | ~$14B |
| Base | $60B | 45% | ~$27B |
| Bull | $90B | 55% | ~$50B |
The key logic: SK hynix does not need to defend 60%+ forever for the thesis to work. If the market triples or quadruples, even a normalizing share can mean far higher absolute revenue and profit dollars. And the SAM grows along two axes at once — volume (more accelerators, racks, inference) and value (more HBM per accelerator, more expensive stacks, more logic content, more customization). That is why AI HBM is structurally better than old DRAM, which expanded mainly through more bits.
SK hynix does not need to own all of AI memory. It only needs to remain a leader in the part of memory that AI cannot scale without.
9. Why the re-rating isn’t finished
The market-structure tell is the forecasts themselves. TrendForce has raised its global memory market view to more than US$1.28 trillion by 2027 (≈44% annual growth), up from $842.7B, explicitly attributing the structural expansion to the shift from training toward inference-centric agentic AI — and flagging KV-cache scaling, CPU-to-GPU ratios moving from 1:8 toward 1:4 and even 1:2, and HBM wafer consumption compressing conventional DRAM and strengthening pricing power into 2027.
Numbers re-based that hard, that recently, tell you the consensus is still catching up to itself. The community has accepted that memory pricing is strong. What it has not fully re-rated is the category claim: that memory is becoming a platform-critical, qualification-moated, logic-rich layer that may rival the GPU in importance into Feynman. Those re-rate to different multiples.
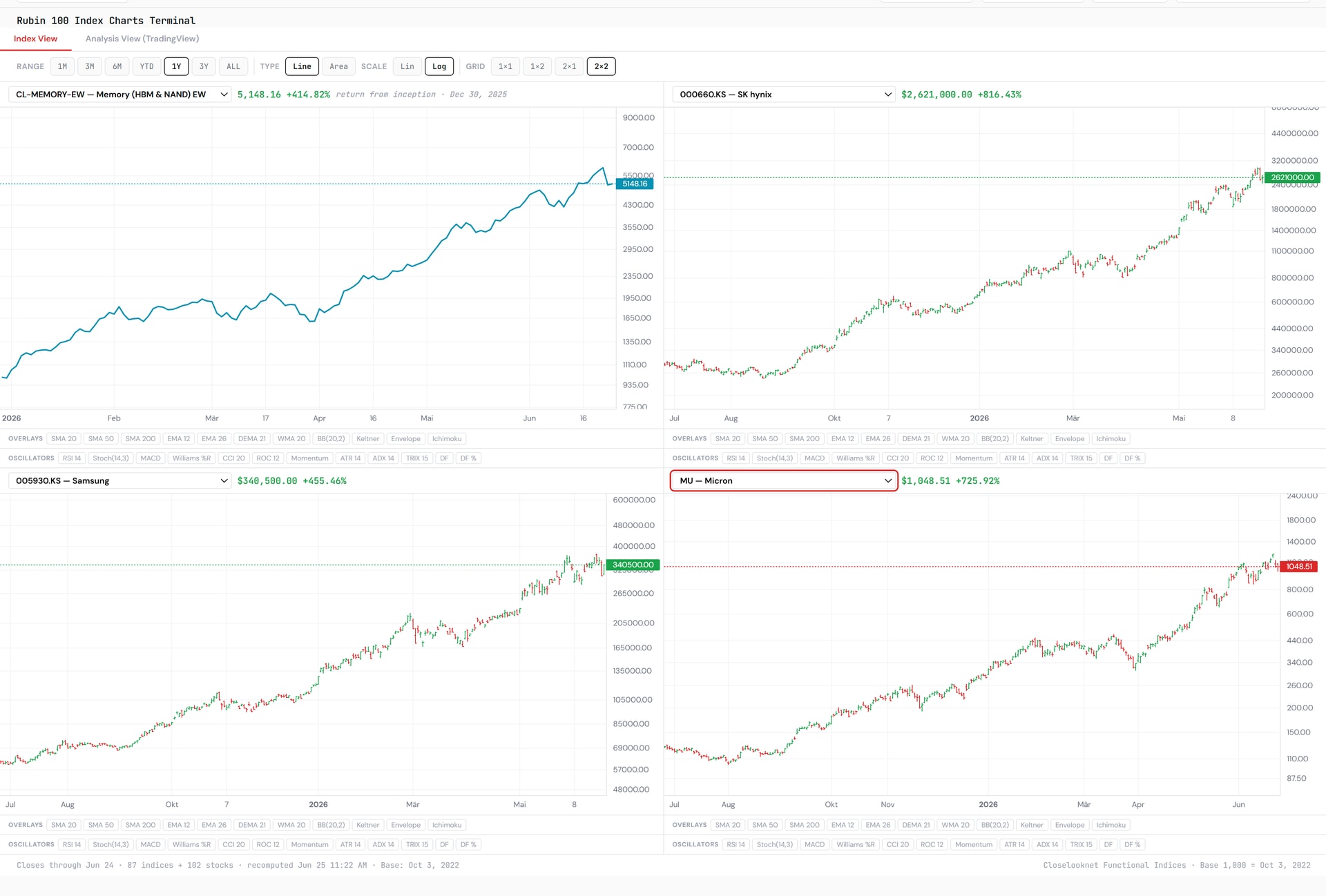
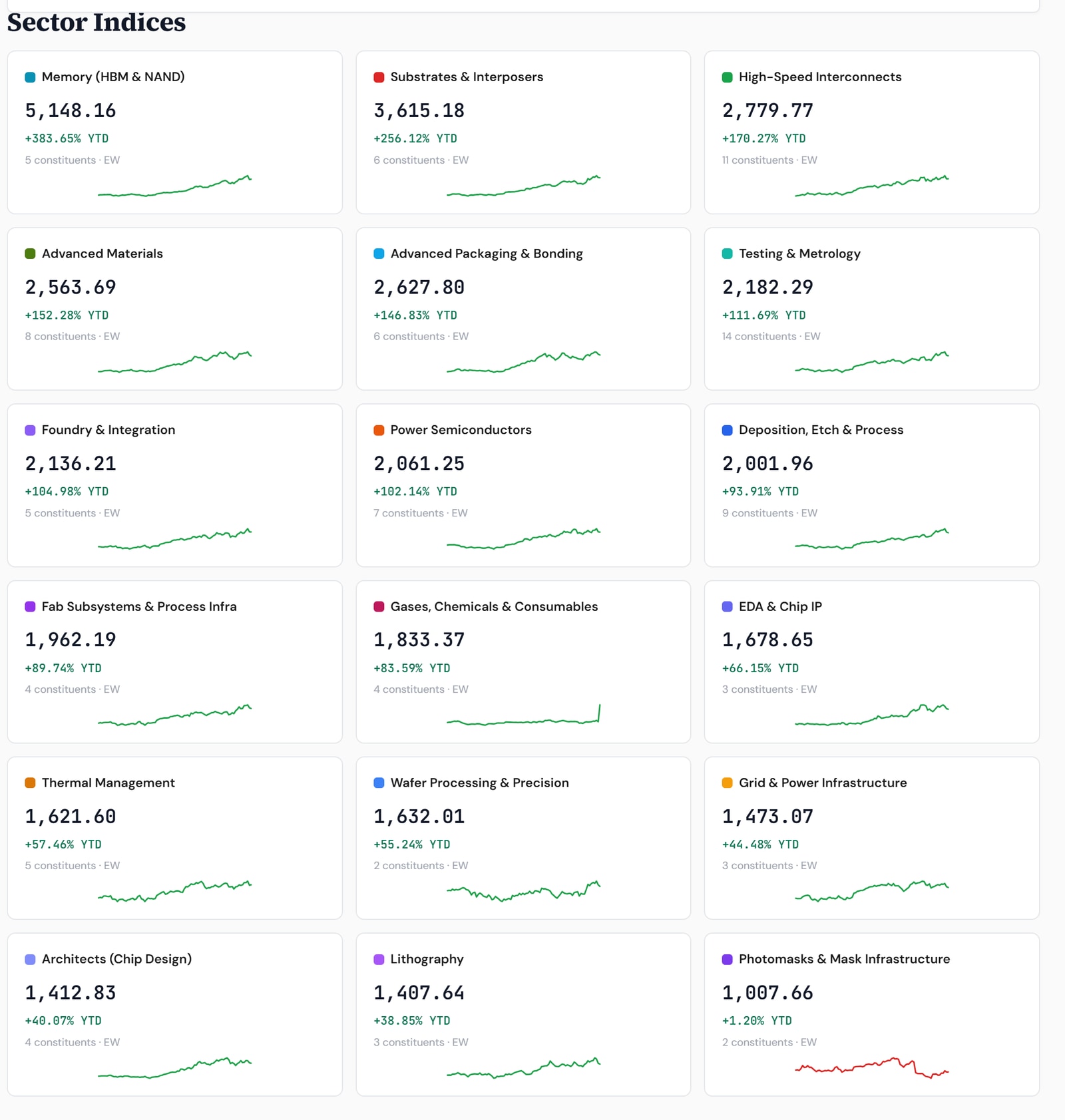
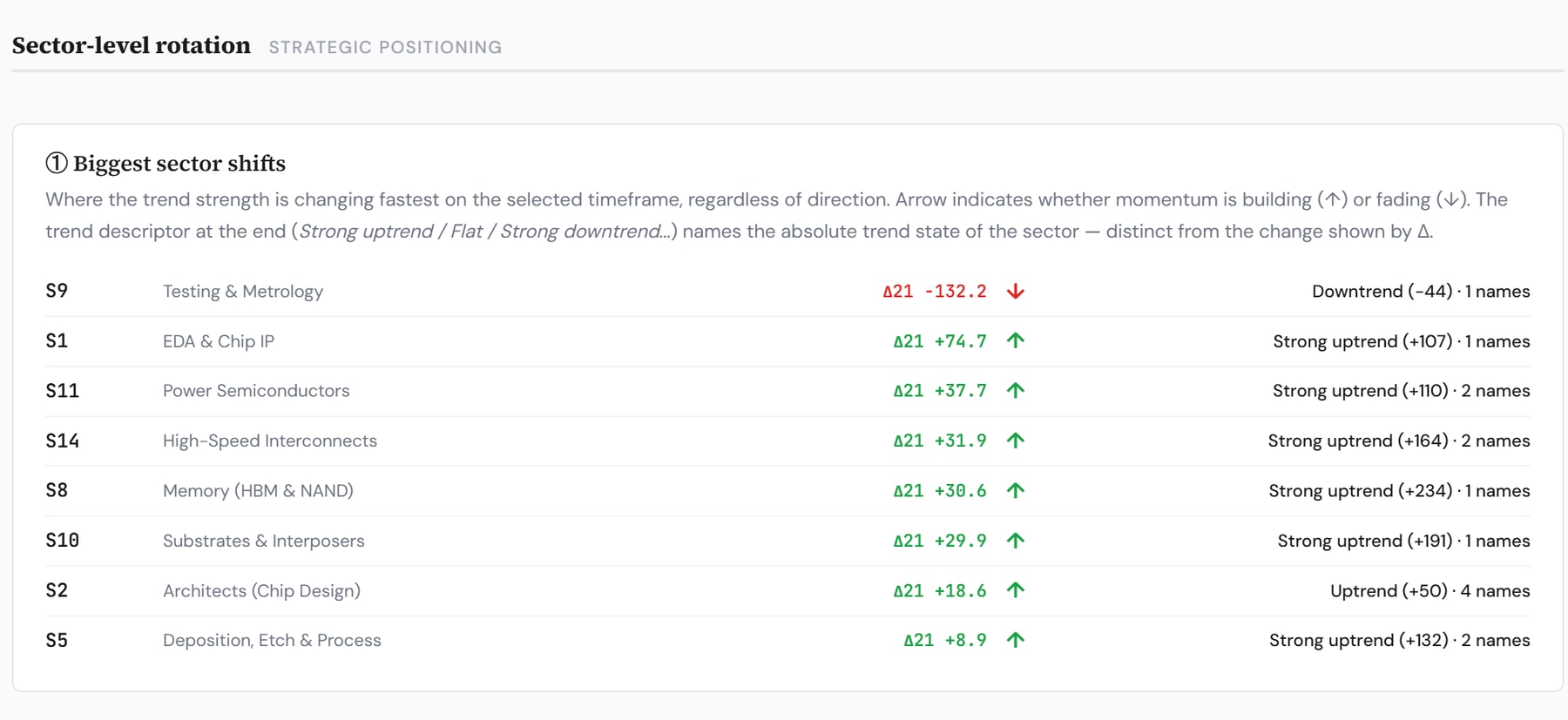
This maps onto our Generation Rotation Framework. We have the cycle in Rubin Early Ramp — the phase where Memory, Packaging and Substrates lead — and the dashboards agree: Memory is the single strongest sub-index of the Rubin Build-Out 100, +383.65% year to date, ahead of all seventeen other layers, and it carries the strongest absolute trend state on our sector-rotation board. The framework’s whole point is that the sectors are permanent and leadership rotates; the argument above is that memory’s leadership stays relevant far longer than a single ramp.
10. What could break this — the two ways the wall comes down
A heresy that says “memory is the new compute” owes you the honest counter-case. This thesis fails in one of two ways — and only one of them is the old commodity cycle.
The demand attack: software makes the wall lower. The cleanest bear case is not oversupply — it is efficiency. If algorithms make each token need less memory — KV-cache compression, better attention kernels, sparsity and Mixture-of-Experts routing, lower precision such as FP4/INT4 — then the “memory scales with the workload” assumption weakens at its root. This is not hypothetical: a Google research result in spring 2026 pointing at exactly this kind of efficiency triggered a mini-crash in memory stocks. The DeepSeek-style “do far more with far less” shock is always one paper away, and more breakthroughs are coming. The same compute-efficiency story that powers the AI trade can quietly decompress memory demand — and the memory complex, carrying the highest beta in the build-out, would feel it first.
Watch the efficiency papers as closely as the capacity roadmap. The wall does not have to be oversupplied to come down; it only has to be made less necessary.
The routing-around: the special NVIDIA angle. The constraint can also be engineered around, and NVIDIA has more levers than the bull case admits. It can push HBM density (GB300 already moved to 288 GB HBM3e per GPU, up from 192 GB; Rubin’s HBM4 nearly triples bandwidth versus Blackwell), pool memory across the rack (GB300 NVL72 turns 72 GPUs into a ~21 TB HBM pool, solving locality at the system level), lift bandwidth, not just capacity (HBM4 in the 20+ TB/s class), lean on its software stack (CUDA, TensorRT-LLM, quantization, KV-cache compression, speculative decoding) to extract more real throughput per GB, split product lines to non-HBM SKUs (a Rubin CPX reportedly designed around GDDR7 rather than HBM — since reported delayed — to reserve scarce HBM for training), and lock up supply through prepayments and co-engineering with the memory vendors.
Here is the nuance that decides whether this matters. Most of those levers are bullish for HBM volume — more density, more bandwidth, and supply lock-up all mean more HBM for SK hynix, Micron and Samsung, not less. The two that actually bite the memory-maker case are the efficiency lever (software doing more per GB) and the substitution lever (GDDR7 or system memory taking the low-bandwidth inference tier). NVIDIA reroutes the constraint mostly by scaling the memory system up, which reinforces the suppliers — right up until a software or substitution step-change lets it scale memory down. The real swing factor is not “is NVIDIA blocked by memory?” but “does capacity stay the thing customers compete on?” — the world in which AMD and custom ASICs fight hardest on gigabytes per accelerator.
So the structural-demand floor — agentic state, KV-cache, an upgrade every accelerator generation — is real, but it is not immune. The way this thesis fails is not a glut; it is a breakthrough that makes the wall lower, or an architecture that routes around it. That risk is the price of admission for owning the highest-beta layer of the AI build-out — which is exactly why the next section frames this as an ownership discipline, not a one-way bet.
11. The distinction that matters for positioning
The old memory trade was a timing trade: buy the bottom, sell the peak. The new memory thesis is an ownership thesis: own the companies that control the memory wall of AI. How we hold it: SK hynix is the cleanest expression of that ownership today, with Micron as the diversification leg and Samsung as the integrated-stack optionality. The wider value chain travels with them — advanced packaging (TSMC, Samsung), substrates and interposers, base-die/controller logic, test and inspection (stacked-HBM yield is hard), thermal and power, and tiered memory/storage for KV-cache offload. Once the rack is the computer, the memory hierarchy is one of the most valuable parts of the computer. Common vehicles for this exposure run from the makers themselves to the broad memory and semiconductor ETFs.
None of this repeals cyclicality. Keep the risks in view: inventory and capex cycles, contract-price air-pockets, customer concentration, export-control exposure, and the simple fact that qualification leadership can shift if a rival nails the logic-die transition. The heresy is not “memory only goes up.” It is: stop modeling memory as a commodity you rent at the bottom of a cycle, and start modeling it as a logic-rich platform layer you own through a multi-generation upgrade wall.
The takeaway
In the PC era, memory was about units. In the AI era, memory is about tokens. In the agentic era, memory is about state — context, cache, reasoning steps, documents, tool calls and persistent workflows — and increasingly about logic, as the base die absorbs the work that used to belong to the accelerator.
That is why HBM4 is special, why it is Rubin’s bottleneck, and why HBM4E and HBM5 are not optional. Rubin doesn’t just need more compute; it needs memory fast enough, dense enough, close enough, efficient enough — and now smart enough — to keep agentic systems running at scale. The GPU remains the engine. Memory becomes the throttle, the fuel line, and increasingly part of the control system itself. The memory wall is becoming the AI economy’s toll road. The market is paying the toll. It hasn’t finished pricing the road.
Heresies is a series of contrarian investment theses. This is reference-portfolio commentary, not individual investment advice — and we hold skin in the game on the themes we write about. Market-share, TAM and growth figures reflect the cited sources (JEDEC, Micron, SK hynix, TrendForce/The Elec, Chosun Biz, Tom’s Hardware, Mordor Intelligence, UBS) as point-in-time estimates; the SOM table is a scenario framework, not a forecast.